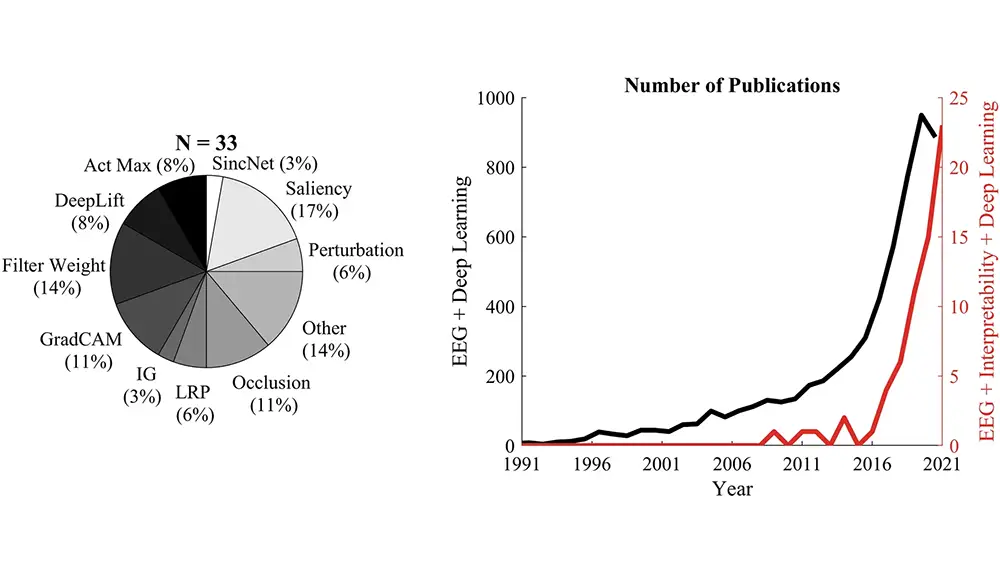
Recent advancements in machine learning and deep learning (DL) based neural decoders have significantly improved decoding capabilities using scalp electroencephalography (EEG). However, the interpretability of DL models remains an under-explored area. In this study, we compared multiple model explanation methods to identify the most suitable method for EEG and understand when some of these approaches might fail. A simulation framework was developed to evaluate the robustness and sensitivity of twelve back-propagation-based visualization methods by comparing to ground truth features. Multiple methods tested here showed reliability issues after randomizing either model weights or labels: e.g., the saliency approach, which is the most used visualization technique in EEG, was not class or model-specific. We found that DeepLift was consistently accurate as well as robust to detect the three key attributes tested here (temporal, spatial, and spectral precision). Overall, this study provides a review of model explanation methods for DL-based neural decoders and recommendations to understand when some of these methods fail and what they can capture in EEG.
Link to full Article: https://www.nature.com/articles/s41598-023-43871-8


Leave a Reply